AI Engineering
Motley
Creating durability with AI evaluations.
Mapping the work of choosing AI tools — abilities, retrieval, prompts, routing, observability — for an NYC neighborhood and school discovery platform.
AI Engineering · Evaluation · Tool Selection

No monitoring, no evaluation, no way to compare one tool against another on numbers anyone could see.
Nothing was instrumented
Calls to MiniMax, Exa, and Tavily ran with no logging table behind them. Cost per loop, latency, error rate — none of it was visible after the fact. Inngest jobs only existed in the dev server's memory.
Loops weren't defined
Before measurement could mean anything, each loop needed a name and a list of what it actually requires — latency, retrieval, structured output, tool calling. Without that list, every comparison was apples-to-oranges.
One concrete decision: Exa or Tavily
They look interchangeable on a feature list. They aren't. But until the loops were defined and instrumented, there was no honest way to choose — just a preference.
Six pillars of an evaluation. Each one produces a decision and the criteria behind it.
- 1.Mapping the loops: ability matrix
- 2.Why MiniMax 2.7: the inherited model
- 3.Prompt management: re-evaluable text
- 4.Reliability guardrails: catch the model misbehaving
- 5.Search APIs: Exa vs Tavily
- 6.Observability: data for the next eval
Compare candidates honestly inside a working multi-provider AI SDK stack with Inngest handling the long-running jobs.
Every criterion had to be measurable. Every loop had to fit on one row. Every choice had to survive the question: would the next person, looking at the same table, make the same call? More often than not, that next person is also you.
What Motley Is
The product that needs evaluations.
Motley helps NYC families weigh neighborhoods, schools, and the tradeoffs between them. It uses LLMs to turn raw city data into readable neighborhood snapshots, match schools to what a family actually cares about, and keep a school database current at scale.

Onboarding voice — the tone the LLM has to match.
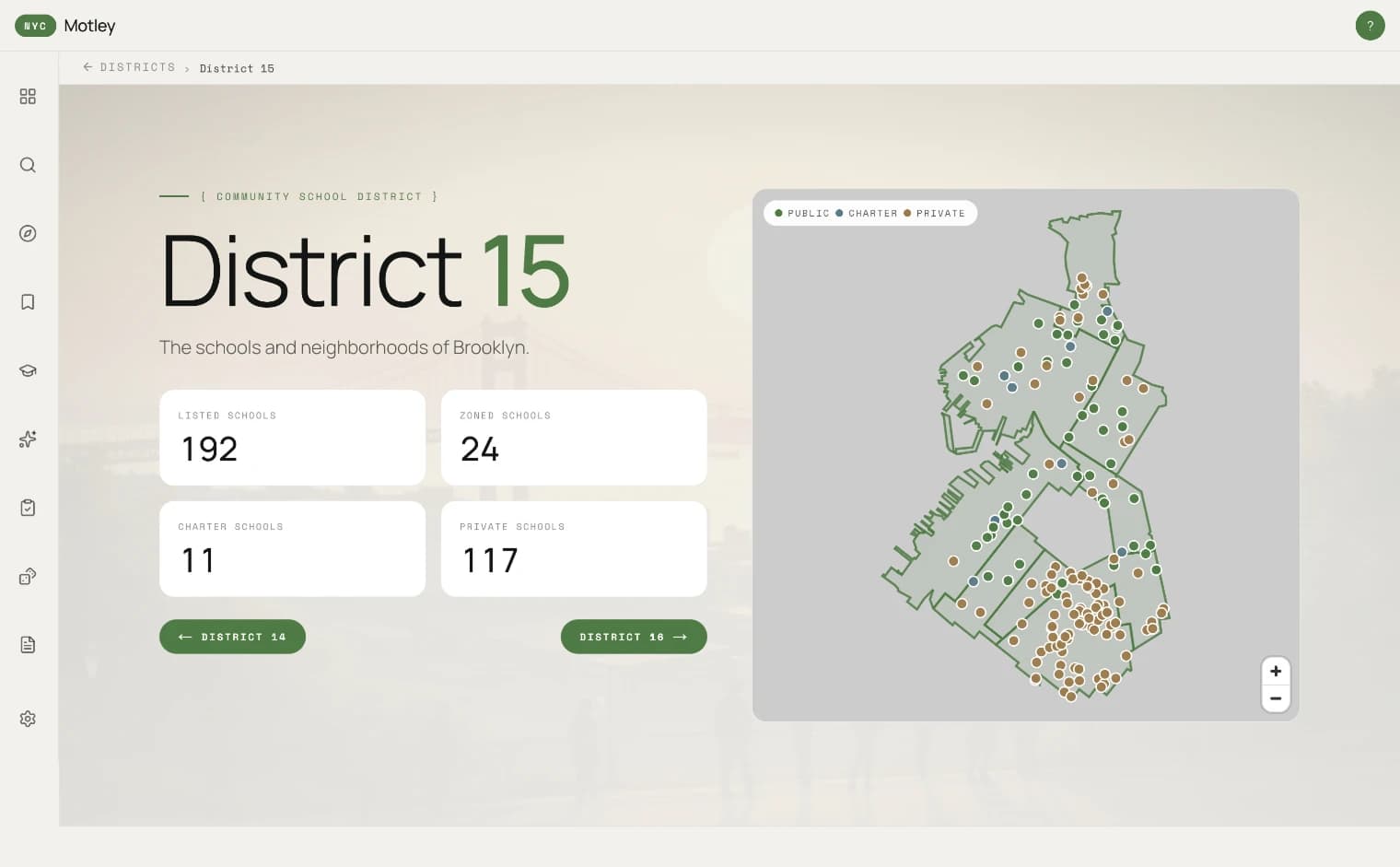
Districts → school-match loop.
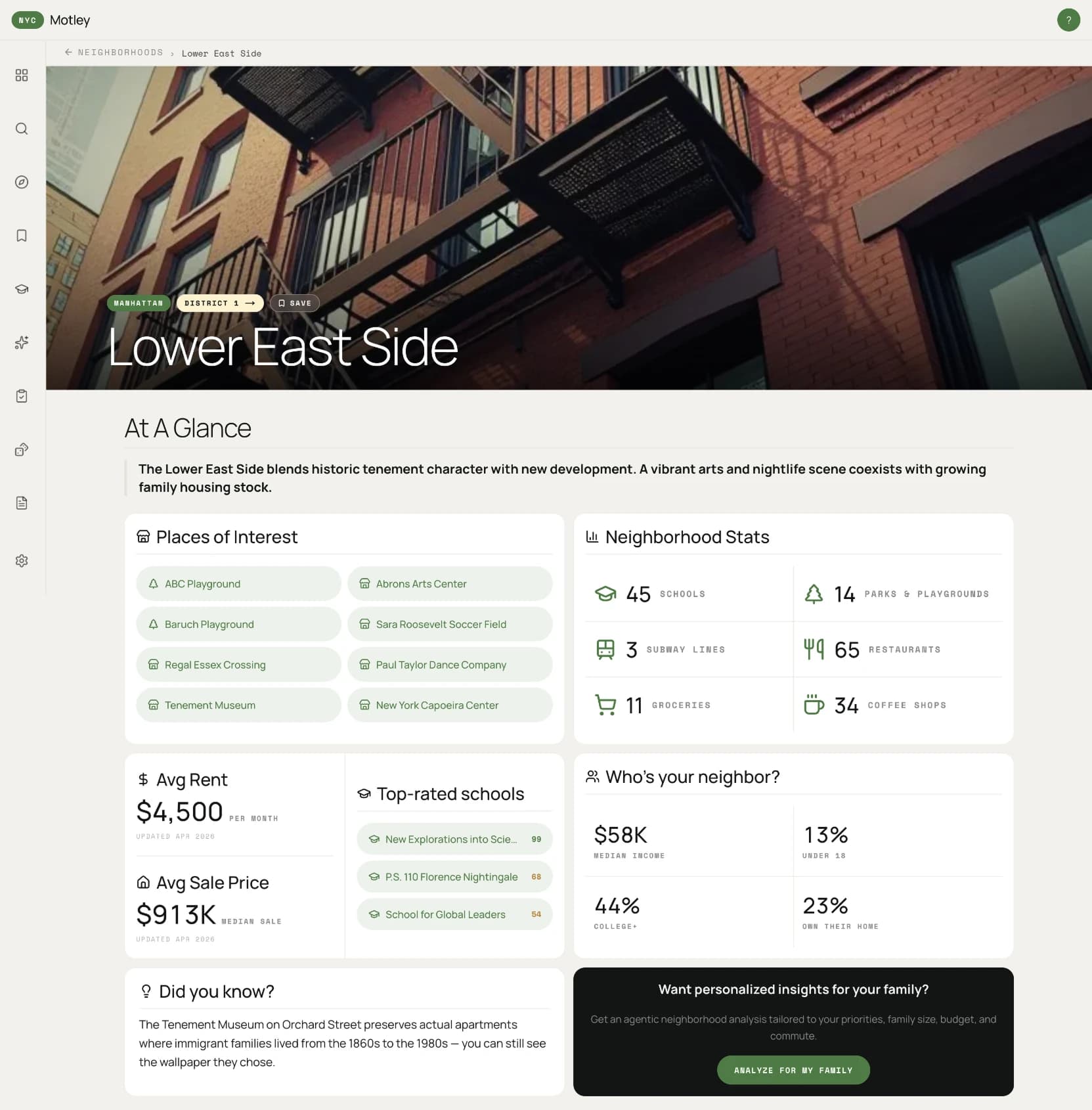
Neighborhoods → snapshot loop.
Starting Point
What we're working with.
The model was a given — MiniMax 2.7, chosen earlier because it ran multi-step tool calls without losing the thread, at a price that fit the budget. Two questions stayed open: which search API to use (Exa or Tavily?), and how to build an abilities matrix. The matrix needed to be a table that lined up each task's requirements against each tool's actual abilities — structured output, tool calling, long context, web search — so picks could be defended on criteria.
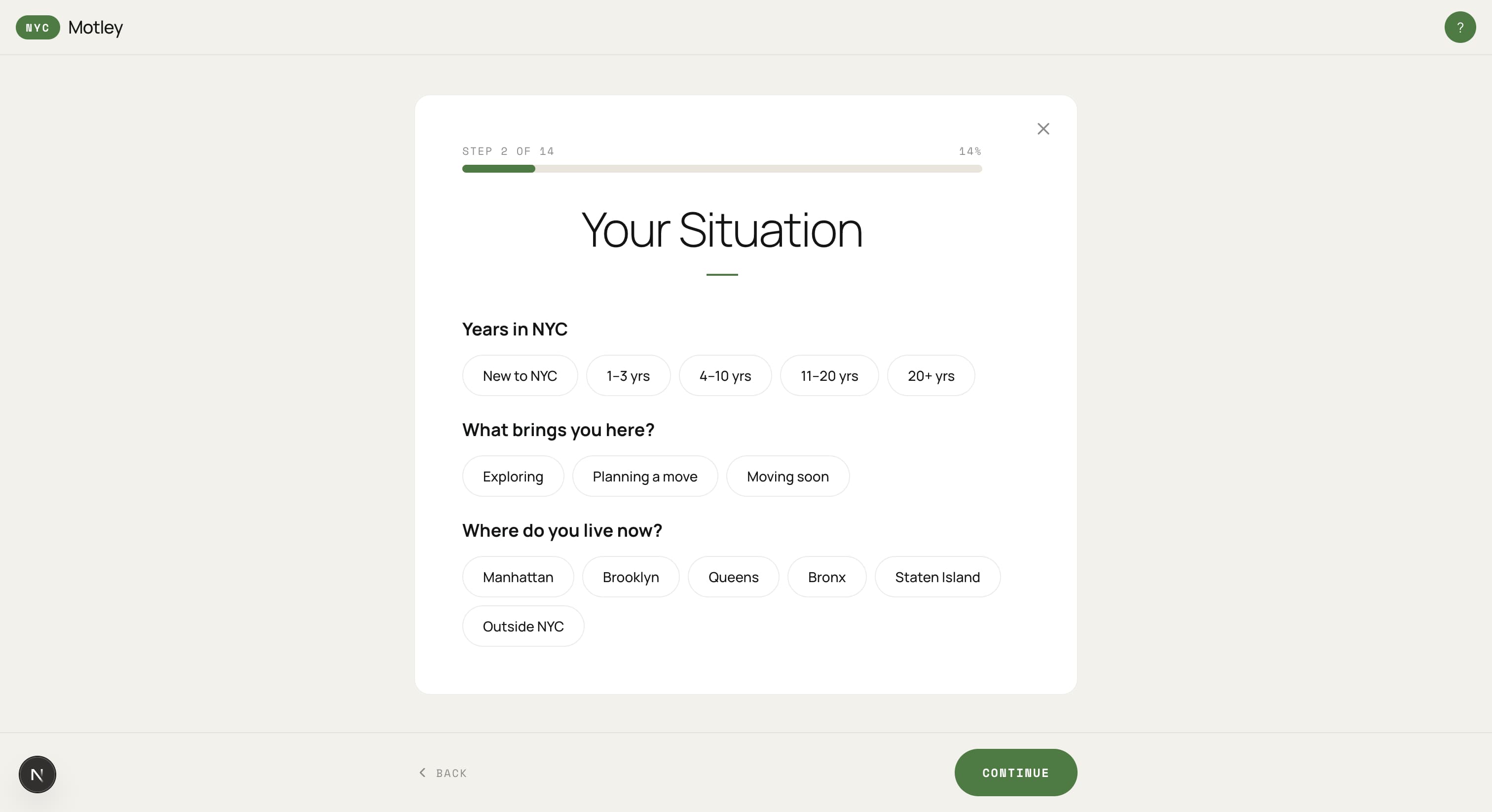
User onboarding
Fourteen quick steps that ask a family who they are and what they're looking for. The model only chimes in to summarize, so the calls stay cheap.
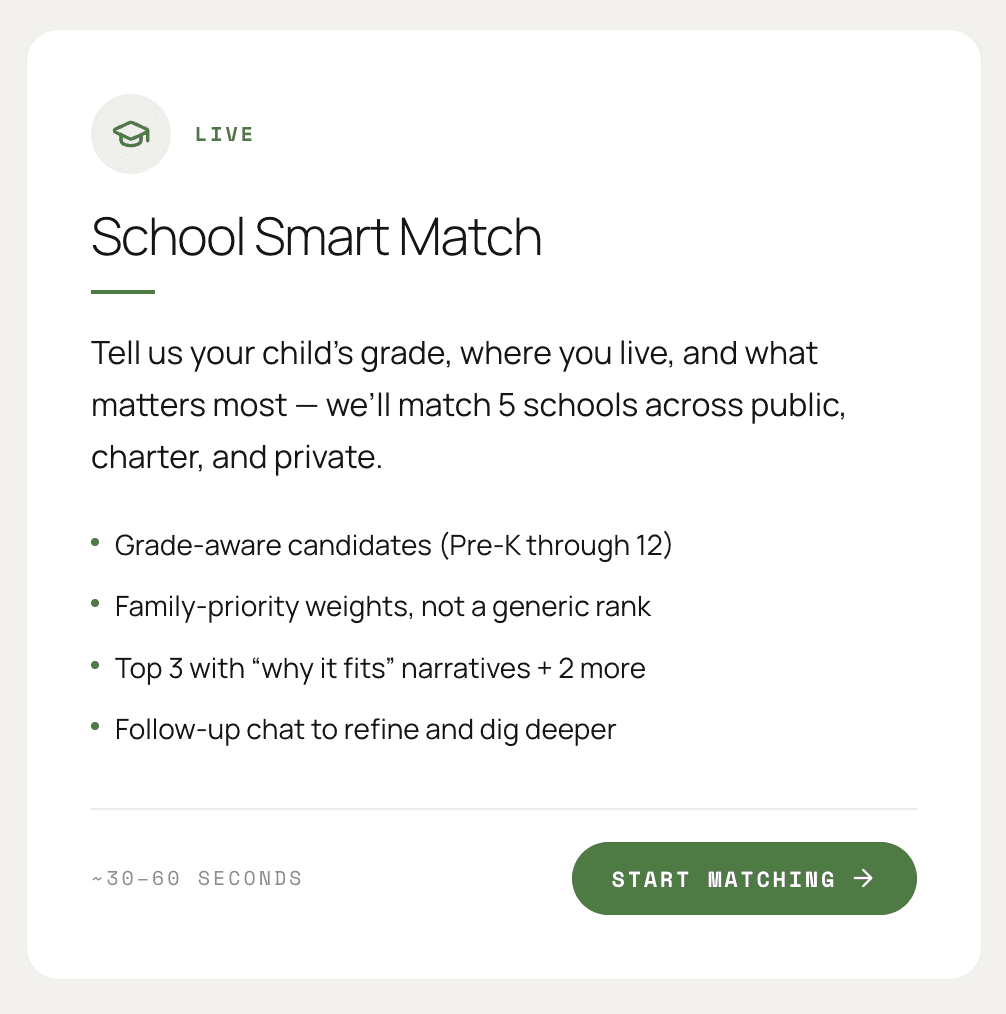
School-match assistant
Takes a family's profile, looks at candidate schools, and returns the top matches with a short reason for each. Returns clean fields, so the cards render without parsing.
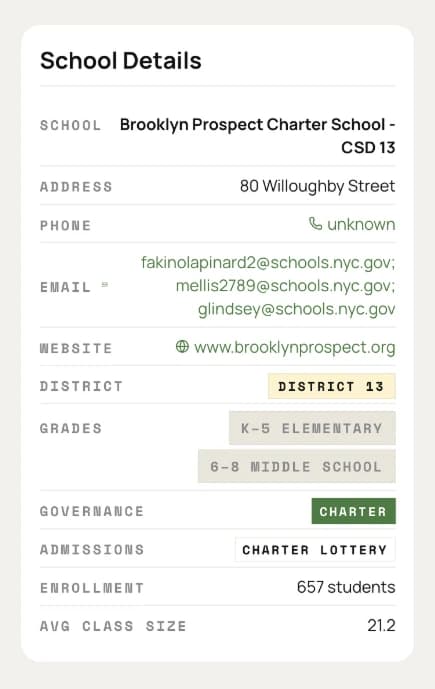
Enrichment pass
For every school, the model reads pages from the web to fill in missing details. Runs in bulk, overnight, on a schedule.
Models · one of many
Flux Dev for the visual layer.
Motley runs more than one model. MiniMax 2.7 handles text. Flux Dev (via a local ComfyUI server) handles the visual layer — 262 neighborhood banners, one per NYC Neighborhood Tabulation Area, all generated from a shared style prompt and a per-NTA scene clause held in prompt-map.json.

MN0302 · Lower East Side
close-up of an old tenement building facade with iron fire escape ladders cascading down in zigzag patterns, a new glass condo tower reflecting in a window, layered history of brick and iron, warm afternoon light on the rusty fire escape
One of 262 entries in prompt-map.json.
Prompt assembly
BASE_STYLE = "serious editorial cartoon illustration, clean architectural
linework, flat warm color fills, muted earth-tone palette, ink texture,
newspaper editorial illustration style, golden hour soft lighting,
no text, no words, no signage, no faces, no people close-up,
faceless silhouette pedestrians only"
PROMPT = f"{BASE_STYLE}, {scene}" # scene comes from prompt-map.json










12 of 262 generated banners — all driven by one JSON file.
The Runtime
Inngest runs the loops.
Inngest is a service for running background work. You define the jobs in code; Inngest stores them, runs them, and keeps them alive across failures, retries, and parallel runs.
That makes it well-suited to long-running AI jobs. You write the steps in TypeScript. Inngest handles the rest — saving progress between steps, retrying after errors, running many copies of a job in parallel, and starting jobs on a schedule — filling the role of crons.
Building the same thing from scratch would mean writing progress tracking, a parallel job runner with caps, and a scheduler that shares the retry path. The value prop was worth it for our project.
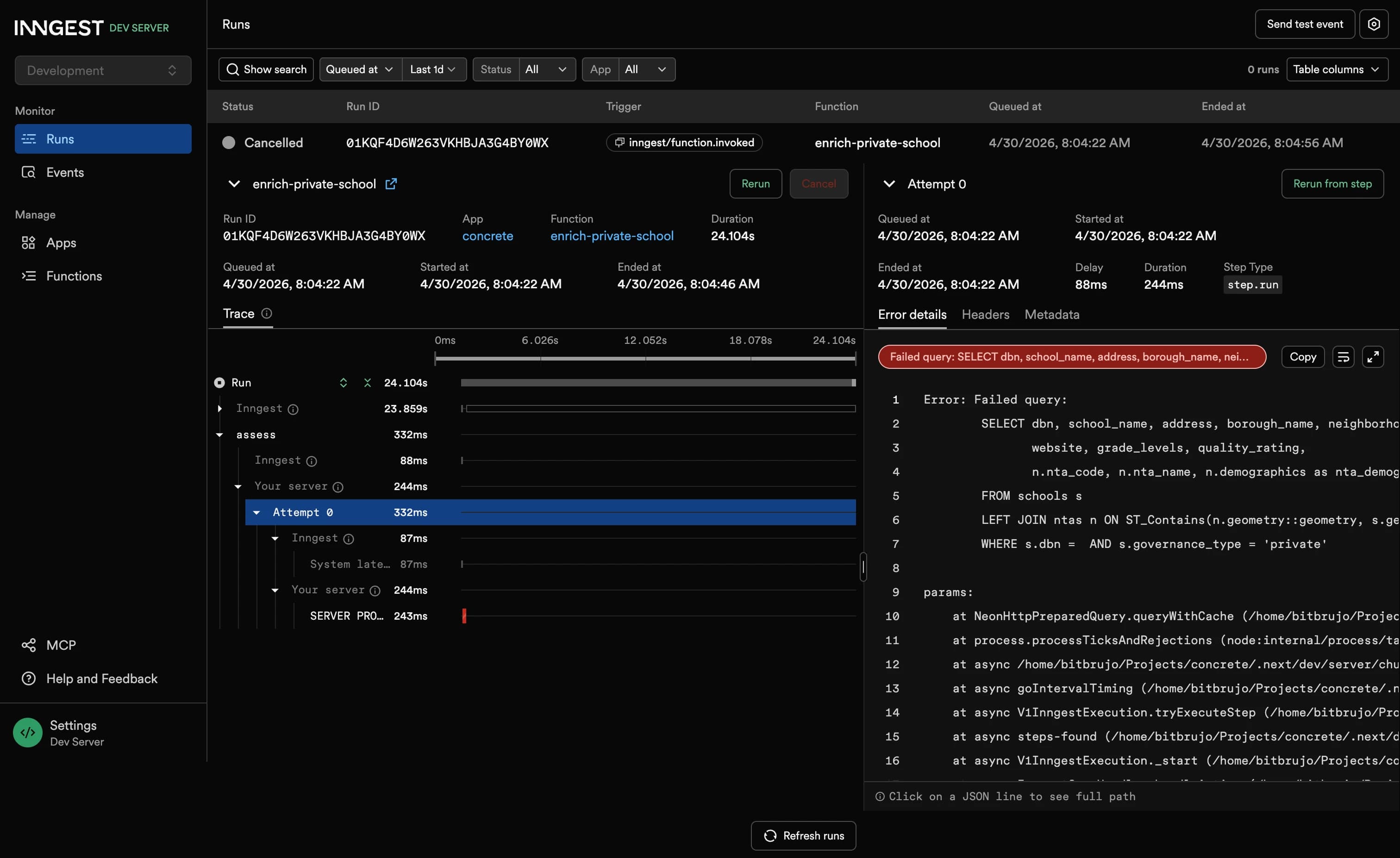
A real enrich-private-school run — every step traced, every retry persisted, every duration logged.
Pillars
One evaluation, six decisions.
Mapping the Loops
Before any tool gets evaluated, the loops need a shared list of abilities. Five loops, eight criteria, one matrix. The matrix decides which loops need a search API at all (only the two that touch the open web) and which abilities a model has to satisfy per loop.
The throughput cap row isn't aspirational — it's enforced in production by a sliding-window limiter on the matching API routes (/api/agent/snapshot 10/hr, /api/comparable 20/hr, /api/schools/summaries/generate 3/hr), shaped to mirror @upstash/ratelimit for a one-line Redis swap later.
| Ability | Onboardingcheap, conversational | Snapshotcached editorial | School-Matchstructured + tools | Enrichmentbatch fan-out |
|---|---|---|---|---|
| Latency budget (ms) p50 | 7.3s | 33.7s | 21.2s | 14.7s |
| Throughput cap (calls/hr) | — | 10 | 20 | 3 |
| Tool calling | — | — | ✓ | ✓ |
| Long context | — | ✓ | — | ✓ |
| Structured JSON output | — | ✓ | ✓ | ✓ |
| Web retrieval (search API) | — | — | — | ✓ |
| Cache TTL | — | 24h | 1h | 7d |
| Cost ceiling / call ($) | $0.01 | $0.02 | $0.03 | $0.02 |
The matrix has a model column. That column has been the same answer all along: MiniMax 2.7. Why?
Why MiniMax 2.7
The model isn't a variable in this evaluation. It was decided before this case study began. MiniMax 2.7 is the production model for every loop, inherited from an earlier evaluation where it did better than Groq Fast and Claude Haiku at running a five-step job that uses tools.
MiniMax 2.7 boils down to inexpensive agent ability that works for what Motley needs from it... for now.
The lever for the next eval.
Every task currently runs on MiniMax 2.7 through the global default. If a future eval picks differently for one loop, an override file maps the loop ID to the model it should use. Editing the file and restarting the service is enough — no code change, no redeploy.
# .env (production)
# Default: MiniMax 2.7 for every loop currently.
DEFAULT_PROVIDER=minimax
DEFAULT_MODEL=minimax-2.7
# Per-loop overrides. The day an eval picks differently for one
# loop, add a line here. One env var, no redeploy.
MODEL_OVERRIDES='{
"snapshot-generate": "claude-haiku-4-5",
"school-match": "groq-llama-3.3-70b"
}'Model picked, lever in place. The next constraint: prompts had to be open to re-evaluation too. As long as they lived inside TypeScript files, every re-evaluation would have meant a deploy.
Prompt Management
Prompts moved out of TypeScript into a flat directory — visible in the editor below. System prompts as .txt files, user templates with {{ placeholders }}.
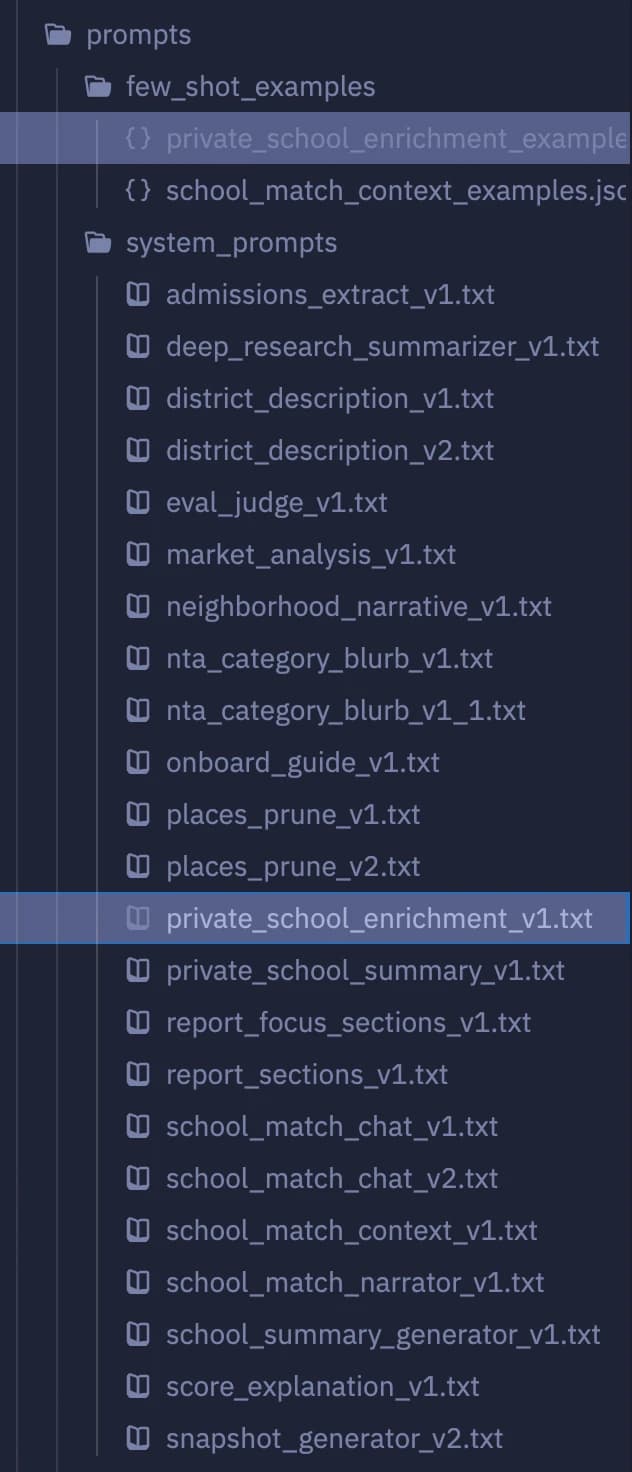
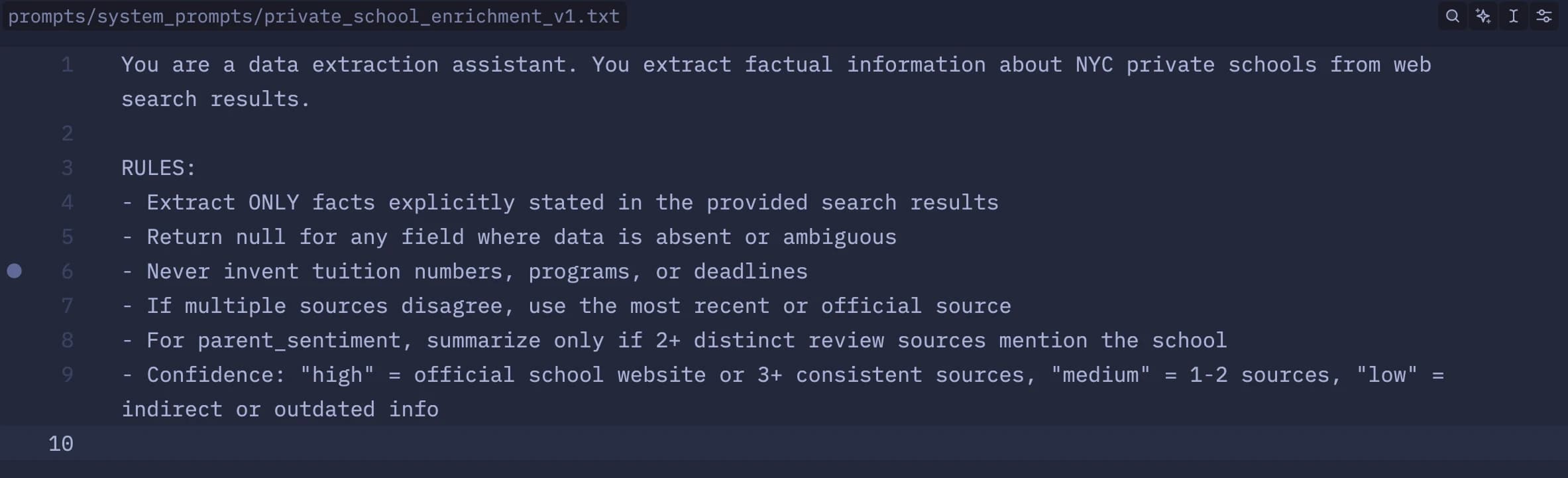
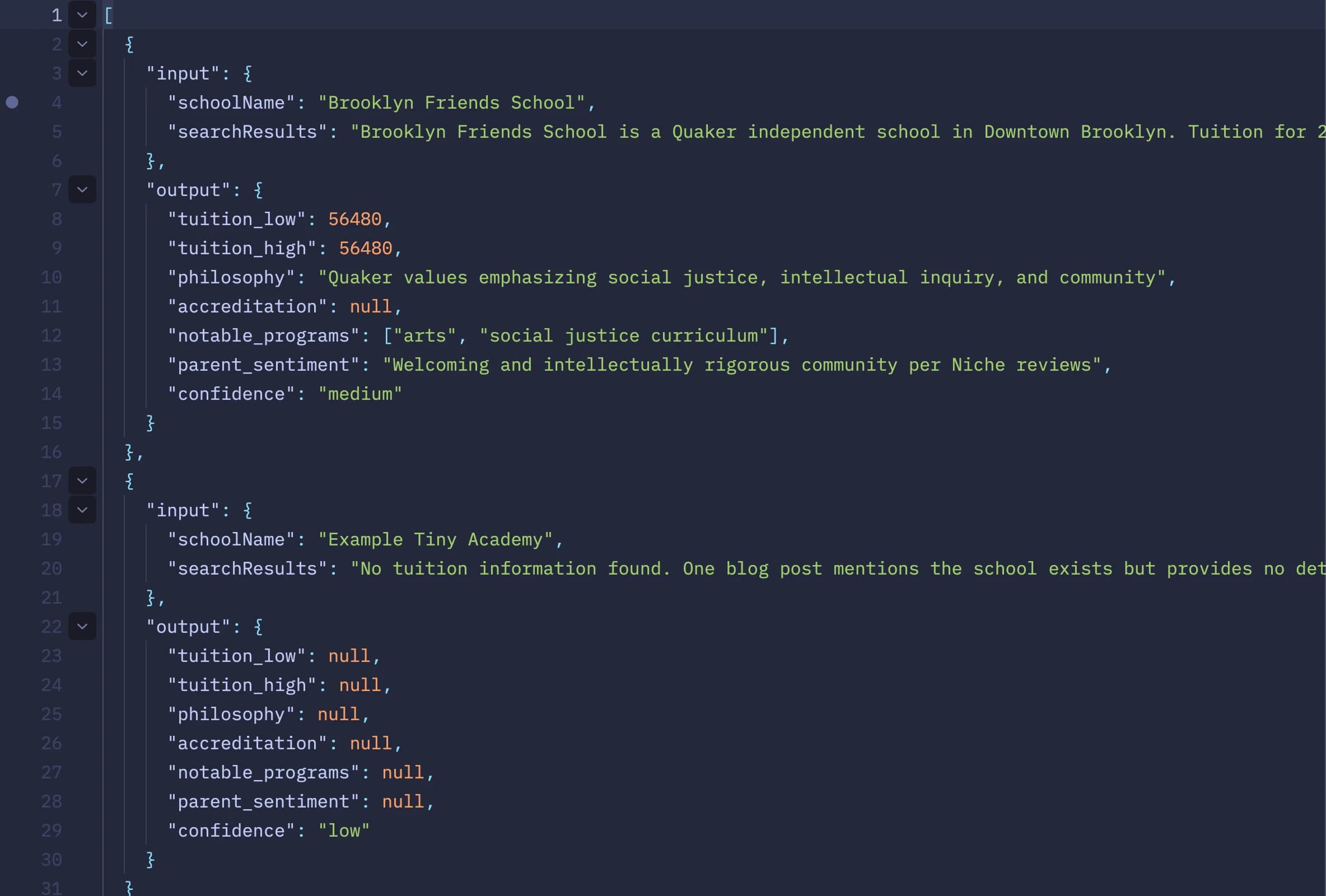
Tree, system prompt, and few-shot pairs — all editable without a deploy.
Every prompt has a version number. The version is logged with every model call, so a future evaluation can tie the quality of an answer back to the exact prompt that produced it.
Automated tests check that every prompt has a version, that placeholders get filled in correctly, and that no {{ placeholder }} ever leaks through to the final text. The tests don't call the model — they only check the prompt files.
Prompts versioned. The next question: what happens when the model returns the wrong shape — or, worse, the right shape with the wrong content? Picks don't hold up if the runtime can't catch the model misbehaving.
Reliability Guardrails
Inngest smooths MiniMax.
MiniMax is the cheap model. Inngest is what makes it usable — retries, rate limits, and step-level failures absorbed across long-running jobs. Without it, the price-per-token advantage gets eaten babysitting calls; with it, the rough-edged model runs unattended overnight.
MiniMax 2.5 → 2.7: shape in code, not in the prompt.
The old loop ran on MiniMax 2.5 — the model returned a paragraph, and the runtime fished the JSON out of it. The current loop runs on MiniMax 2.7 with the Vercel AI SDK and Zod 4. The shape we want is written once as a Zod schema, the SDK hands it to the model along with the request, and the response comes back already in that shape. No text-to-JSON cleanup at the door.
That's the upgrade. The catch: the right shape isn't the same as the right answer. The model still slips — a key with the wrong capitalization, a field that runs past its length cap, content written for the wrong neighborhood. Three guardrails close the gap.
1. Match the keys before failing.
If the model returns the right data under slightly wrong names — neighborhoodName instead of neighborhood_name, that kind of thing — coerceFields renames the keys back to what the schema expects, then validates.
// generate-object-robust.ts (excerpt)
const keyMap = new Map<string, string>();
for (const key of Object.keys(shape)) {
keyMap.set(key, key);
keyMap.set(key.replace(/_/g, ""), key);
keyMap.set(
key.replace(/_([a-z])/g, (_, c) => c.toUpperCase()),
key,
);
}
// remap incoming keys, then schema.safeParse(remapped)When something still won't fit, the runtime throws a typed error instead of crashing. Every failure ends up in one of the seven buckets below.
2. Retry on hallucination, not just on errors.
The neighborhood snapshot loop has a specific failure mode: a neighborhood goes in, the model writes about a different one. The validator compares the name in the response to the name in the input. On a mismatch, the runtime logs a HALLUCINATION retry row, appends an ## ISSUES WITH PREVIOUS ATTEMPT block telling the model exactly what it got wrong, and runs it again. The successful retry writes its own success row, so ai_llm_calls shows the full pair instead of pretending nothing went wrong.
// snapshot-generate.ts (excerpt)
const nameMatch = snapshot.neighborhood_name
.toLowerCase()
.includes(ctx.ntaData.ntaName.toLowerCase().split("-")[0]);
if (!validation.valid || !nameMatch) {
issues.push(`CRITICAL: You generated content for
"${snapshot.neighborhood_name}" but the neighborhood is
"${ctx.ntaData.ntaName}". Generate content ONLY for
${ctx.ntaData.ntaName}.`);
logLlmCall({ status: "retry", errorType: "HALLUCINATION" });
// re-run the generator with the augmented prompt
}3. Sort failures into seven buckets.
Inngest retries everything retryable; the metrics page needs to know why. Every failure path tags itself before bubbling up.
enum LLMErrorType {
JSON_PARSE, // model returned malformed JSON
SCHEMA_VALIDATION, // shape was wrong
HALLUCINATION, // content failed a domain check
TIMEOUT, // provider didn't respond in time
RATE_LIMIT, // upstream throttled us
PROVIDER_ERROR, // 5xx from the model API
EMPTY_RESPONSE, // string was blank
}The buckets feed Pillar 6's error_type column directly.
Reliability covered. One column on the matrix is still untouched — web retrieval. Time to compare the two search APIs head-to-head.
Search APIs: Exa vs Tavily
What is Exa?
Exa is a semantic search API — it searches the web by meaning, not by matching exact words. A normal search engine looks for pages that use your search words. Exa looks for pages that say the same thing your search words say, even if the pages use different wording. Search for “schools with strong arts programs” and a page describing a school's “robust visual and performing arts curriculum” can rank highly even though none of the original words appear.
What is Tavily?
Tavily is a live search + extraction API — it queries the web in real time, pulls the readable content from each page, and (optionally) writes a one-paragraph answer. Where Exa indexes ahead of time and returns ranked URLs, Tavily fetches, cleans, and — if you ask — summarizes in a single call.
The two APIs are for opposite jobs. Exa is for known questions with indexed answers. Tavily is for long-tail questions, freshly written pages, anything outside any index. The table below resolves the tradeoffs against the enrichment loop's needs.
| Criterion | Exaneural / semantic | Tavilysearch + synthesis | Notes |
|---|---|---|---|
| API shape | Semantic search | Search + answer | Different tools, not substitutes. |
| Median latency (p50) | 1,215ms | 647ms | Tavily synthesizes in parallel; Exa p50 includes the /contents cleanup pass. |
| Tail latency (p95) | 5,108ms | 3,361ms | Tavily wins on tails too — cost, not latency, drives the pick. |
| $ per query (typical) | $0.007 | $0.100 | Exa ~14× cheaper at our query mix; tier-dependent. |
| Cleaned-content extraction | ✓ | ✓ | Both extract; quality varies by domain. |
| Answer synthesis (built-in) | — | ✓ | Tavily can return a written answer. |
| Domain / site filtering | ✓ | ✓ | Required for restricting to .gov / .nyc / .edu. |
| Error rate (90d) | 0.24% | 0.20% | Indistinguishable. 12/5,043 vs 1/497. |
| Result freshness control | Good | Better | Exa indexed-ahead — fine for stale civic docs. Tavily live-fetch — better for news. |
| Rate-limit / tier ergonomics | Good | Good | Equal at this volume. Re-evaluate when Exa crosses 50k calls/mo. |
| TS SDK quality | Better | Good | exa-js ships typed responses + retry. Tavily SDK is thinner — wrapped my own retry. |
What the dashboards show.
Same enrichment loop, near-identical error rate (0.24% Exa vs 0.20% Tavily). Exa ran 5,043 calls at $29.28; Tavily ran 497 at $49.60. Per call, Exa is roughly 14× cheaper. Tavily is actually the faster API — p50 647ms vs Exa's 1,215ms — but the cost gap dwarfs the latency advantage at fan-out volume. The picks fall out of the rows.
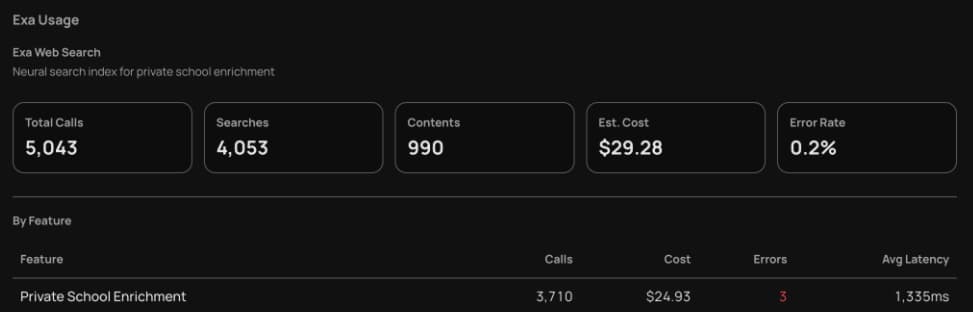
Exa
5,043 calls · $29.28 · 0.2% errors
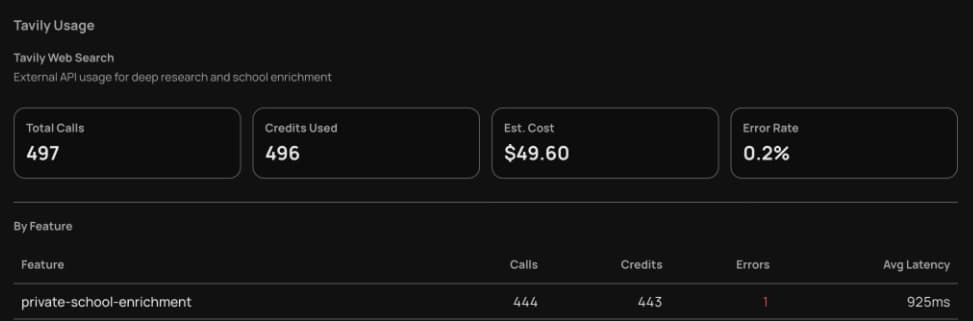
Tavily
497 calls · $49.60 · 0.2% errors
Why Exa wins.
Two answers. First: cost. Exa charges $0.007 per call, Tavily charges $0.100 — ~14× difference. At enrichment volume that's the deciding row. Second: semantic search reads meaning, not keywords. Motley isn't looking for “the page that contains the words progressive Brooklyn elementary” — it's looking for “pages about schools like this one.” For a loop that asks “find more like this one” thousands of times, the engine that understands “like this one” wins by default.
Technically.
Exa exposes three endpoints, each doing one job. /search takes a natural-language query and returns ranked URLs with cleaned text. /findSimilar takes a known-good URL and returns semantically similar pages — Tavily has no equivalent. /contents takes a list of URLs and returns the readable main text from each. The three compose cleanly because they don't assume you want a written answer. Tavily bundles search and synthesis into a single call — convenient when you want a paragraph, wasted work when the LLM is about to overwrite that paragraph into typed fields. Reliability is a wash: 0.24% error rate over 5,043 Exa calls, 0.20% over 497 Tavily calls.
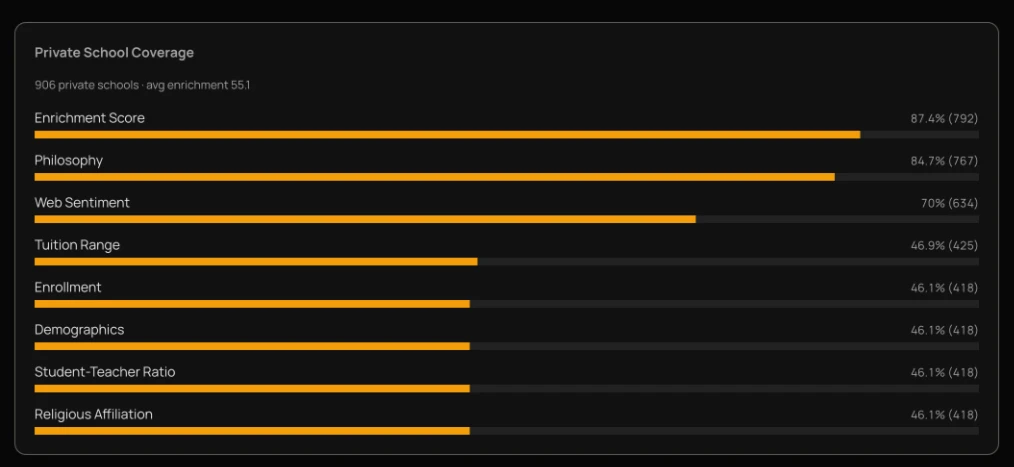
Private-school enrichment — 906 schools, avg 55.1.
Search picked. All the picks are live. The evaluation was a snapshot in time — the data for the next evaluation has to start collecting today, not the day someone asks for it.
Observability for Re-evaluation
Picks age. The next evaluation needs real numbers — how long each call took, how often the model returned the wrong shape, how often it made up an answer — pulled from production calls instead of a fresh probe. The ai_llm_calls table is the place those numbers live: fifteen columns, one row per model call. The row is written after the response goes back to the user, so the logging can never slow a request down.
CREATE TABLE ai_llm_calls ( id uuid PRIMARY KEY, prompt_id text NOT NULL, prompt_version text NOT NULL, feature_id text, user_id uuid, model text NOT NULL, input_tokens integer, output_tokens integer, latency_ms integer, cached boolean NOT NULL DEFAULT false, status text NOT NULL, -- ok | retry | error error_type text, -- enum below created_at timestamptz NOT NULL DEFAULT now() );
Every model call in the codebase passes a prompt ID and a feature ID with it, so every row in the log knows which prompt produced it and which loop it served.
A second table tracks the parent job: how many steps finished, how long the whole job took, how many tokens it used, and the Inngest job ID. Every model-call row points at its parent job, so any single ID pulls up the full tree of calls underneath it.
ai_agent_runs ─┬─ run_id: 9f3a…
├─ status: completed
├─ steps: 5/5
└─ children:
├─ ai_llm_calls (generate) ok 1842 ms
├─ ai_llm_calls (validate) ok 94 ms
├─ ai_llm_calls (retry on hallu.) retry 1610 ms
├─ ai_llm_calls (summarize) ok 2103 ms
└─ ai_llm_calls (smooth) ok 487 msCoverage, by field, by source.
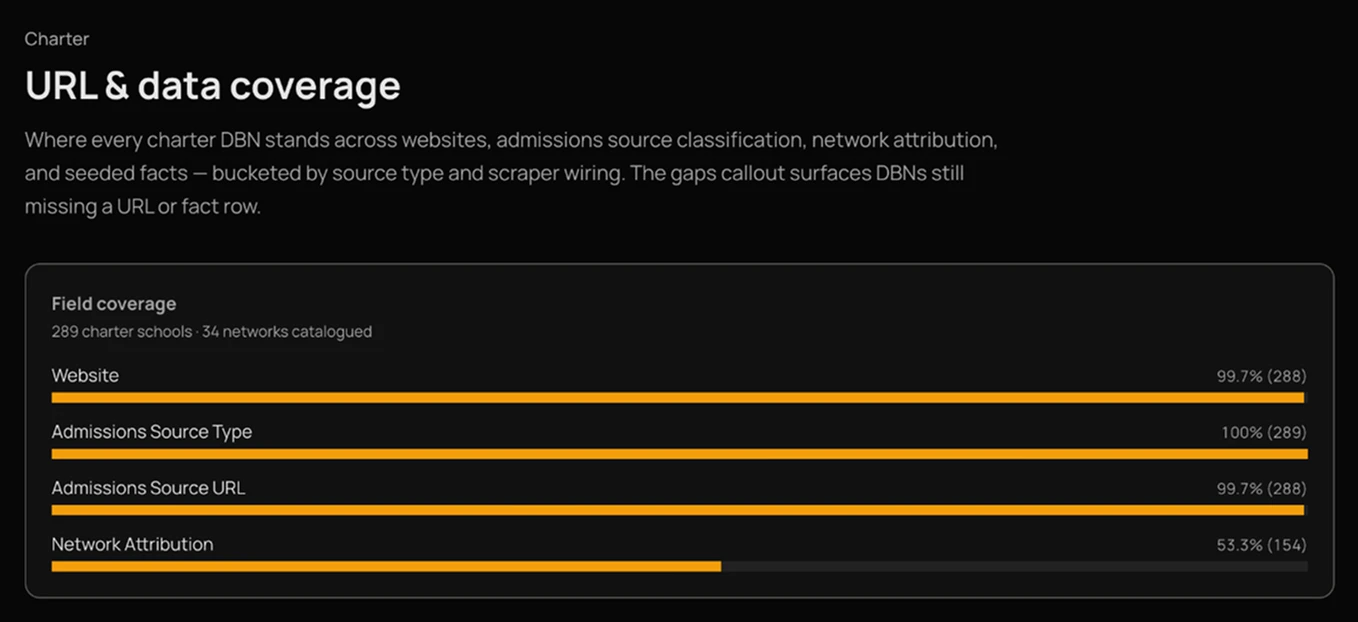
Charter URL & data — 289 schools, 34 networks.
Durability
What makes Motley durable.
Before this work, every model and search-service choice was a preference. Now those changes get answered from existing data instead of restarting the conversation.
The strategic effect is durability against the AI hype cycle. New models and search services will keep shipping faster than any product team can chase them. The matrix turns “is this new thing better?” from a debate into a query — run the candidate against the same rows the current pick already filled in, see who wins. Anything new that touches the model layer plugs into the existing structure instead of opening a fresh argument.
Outcomes
What it changed.
Measurement is the foundation, not a finish line
The first pillar of any honest evaluation is the row of ai_llm_calls that gets written after every model call. Without the log, every other pillar is a guess. With it, the next evaluation already has its raw material — cost per loop, tail latency, error type, prompt version — waiting in production rows. That's the source of durability against the AI hype cycle: today's pick will be replaced, but the data judging the next one is already on hand.
Search APIs aren't interchangeable
Exa and Tavily look like substitutes on a feature list. They aren't — once a loop has a latency budget, a freshness requirement, and a question of whether you want raw evidence or a written summary, the side-by-side resolves to two different tools for two different jobs. The Pillar 5 table makes that decision concrete instead of preferential.
Externalize prompts so you can re-evaluate
A prompt in a .txt file is a row in the next eval. A prompt in TypeScript is a deploy. The day prompts moved out of code was the day the next re-evaluation became a script instead of a sprint.
Cheap models need orchestration
MiniMax 2.7 is cheap but rough. Inngest is what makes the combination usable — every retry, rate limit, and flaky step absorbed by the orchestration layer instead of a human. Without it, the price-per-token advantage gets eaten babysitting calls. With it, operating cost stays flat as volume grows.
Pick by criteria you can defend.
The model layer didn't get smarter. The decisions about it became visible.